Recently I’ve been investigating slow compilation of source files which used one particular library. The library was written in-house and has its roots in pre-C++11 era, including abundant usage of Boost. The library itself provides a sophisticated mechanism of reflection and operates with type-erased objects. Obviously, it heavily relies on the C++ type system and has a lot of template code.
Boost became my primary suspect almost immediately – it’s notorious for compiler torture and I personally try to avoid it wherever possible. So the most prominent red flags like Boost.MPL were almost completely removed and other pieces were converted to their C++11 standardised counterparts. Results, however, weren’t inspiring – compilation time moved a bit, but only marginally. The bottleneck was somewhere else.
Looking at MSVC’s time report (“/d2cgsummary”) didn’t provide anything meaningful – it basically stated that each file contained dozens of functions with “Anomalistic Compile Times”™️. No details why though.
GCC’s time report (“-ftime-report”), on the other hand, was much more helpful. It clearly showed that the lion’s share of time was spent on “phase opt and generate”, which, to my understanding, is actual instructions generation. That was somewhat surprising given the fact that the majority of these source files weren’t large nor performed any rocket surgery.
It should be mentioned that almost all reflection code in that library was written in templates, which makes sense. And, apparently, the compiler was spending time generating instructions for these methods per each instantiation type over and over again for each translation unit, to be later simply thrown away by the linker. It’s hard to estimate the number of instantiation types in the final product itself, but 50-100 can serve as ballpark estimation. So I decided to make an experiment and tried offloading some portions of templated code into a private non-templated “base” class. It immediately became evident that removing even tiny pieces of code, like the formatting of an exception message, results in a reduction of overall object files size (*.obj) by literally megabytes.
In this post I, roughly model the situation with synthetic code generation. Imagine the following pattern (let’s call it Pattern 1):
struct Base { virtual ~Base() = default; virtual void Method(int v) = 0; }; template <typename T> struct Impl : Base { void Method( int v ) override { if( v == 0 ) // some error checking throw std::logic_error ( "you're so unlucky with Method() for \'"s + typeid(T).name() + "\'!" ); // some useful stuff } }; struct Type{}; Base *Spawn_Type() { return new Impl<Type>; }
It’s quite easy to generate such code for a given number of class methods and instantiation types. Each additional method adds an entry in a virtual methods table and a templated implementation in Impl<T> by analogy with Method(). Each additional instantiation type introduces a new type and a new spawning function by analogy with Type / Spawn_Type().
And, for comparison, below is a slightly altered version (Pattern 2). ImplBase provides non-templated functionality and Impl<T> does just the same but redirects the exception composing and throwing to the ImplBase class. Performance hit introduced by additional function call can be neglected in 99.9% of cases.
// [...]
struct ImplBase {
static void ThrowLogicErrorAtMethod( const std::type_info& typeid_t );
};
template <typename T>
struct Impl : Base, private ImplBase {
void Method( int v ) override {
if( v == 0 ) // some error checking
ThrowLogicErrorAtMethod( typeid(T) );
// some useful stuff
}
};
// [...]
This repo contains generators and measurement scripts for both patterns. Scripts execute these generators for each of combinations of [1..20] methods by [1..20] instantiations and measure compilation of produced source code. The measurements shown below were made with “Apple LLVM version 10.0.0 (clang-1000.11.45.5)” on i7-3520M with “-std=c++17 -O2 -c” flags.
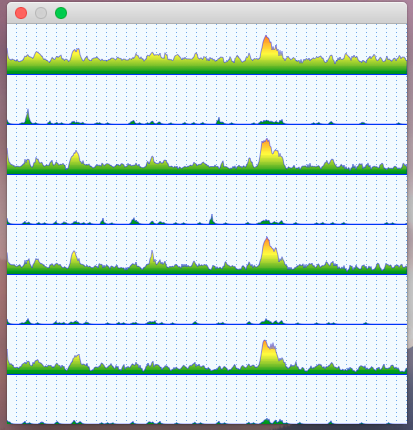
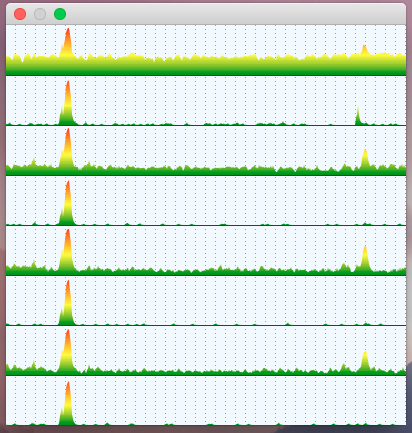
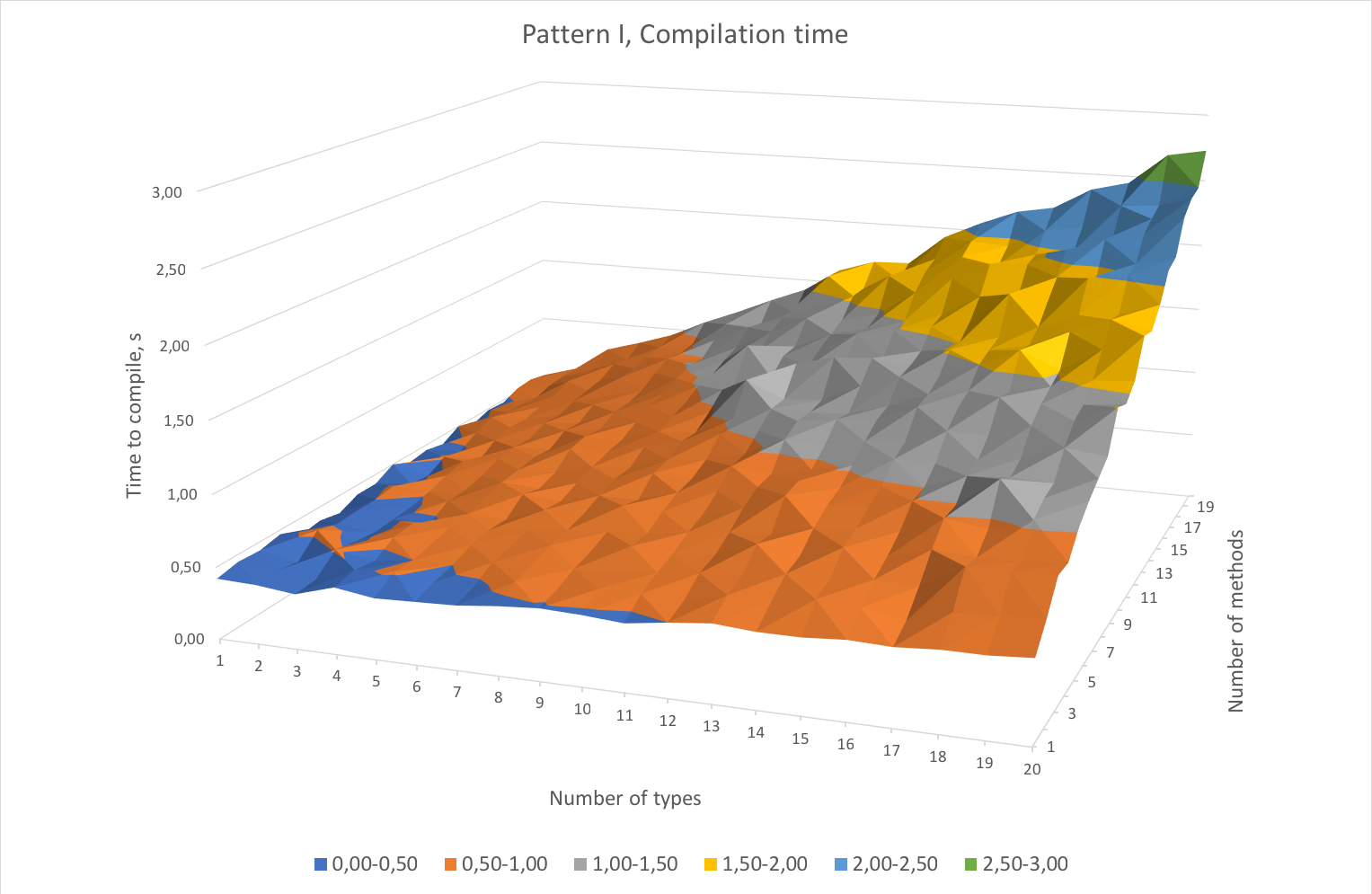
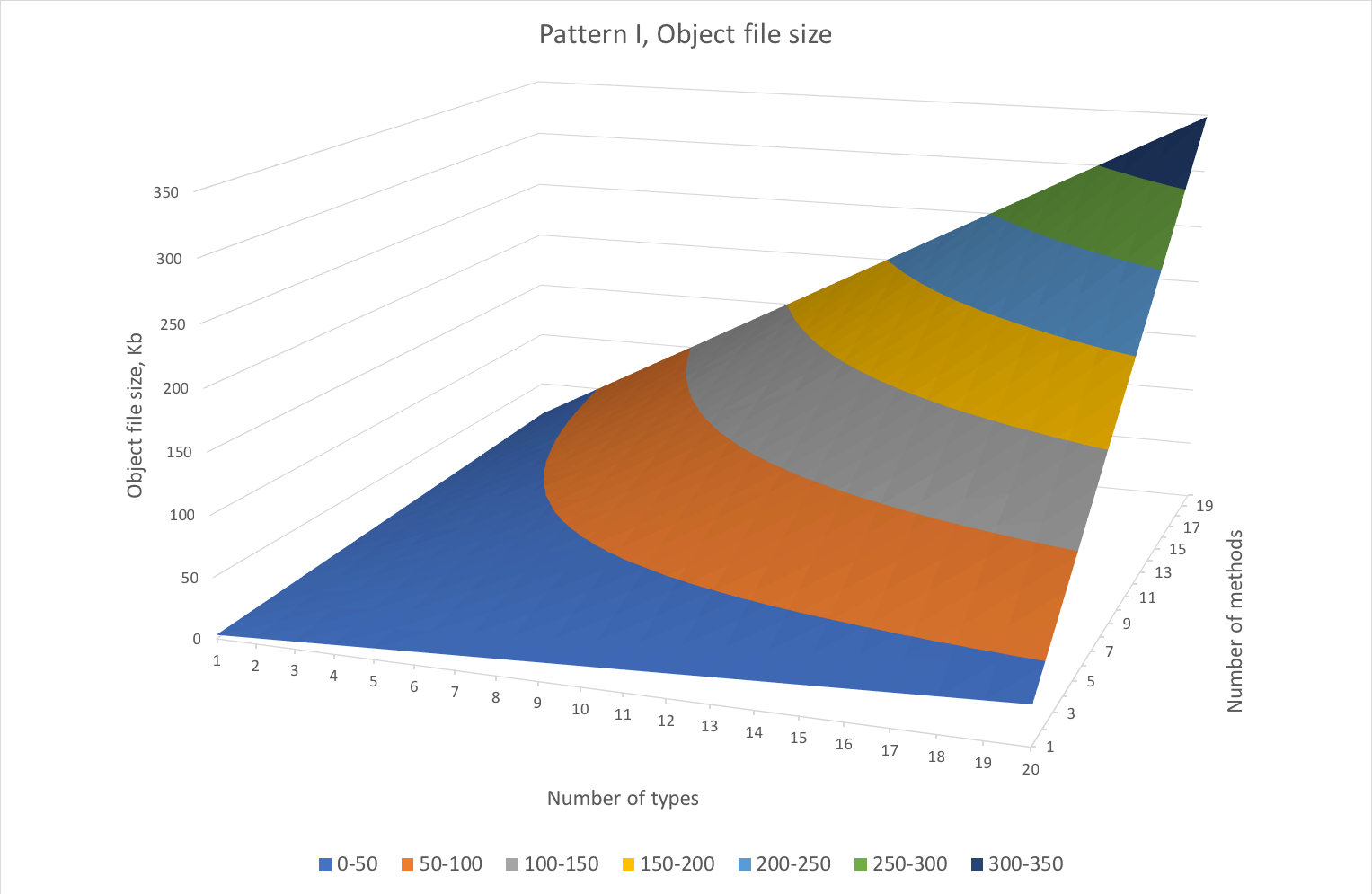
These are the compilation times and the object file sizes for the first pattern. Both compilation time and file size scale roughly proportionally to both number of methods and types. In the worst case scenario (20 methods x 20 types) it takes almost 3 seconds to compile the code which does basically nothing apart from error reporting. If there would be any actual code instead of “// some useful stuff” the graph will look much scarier.
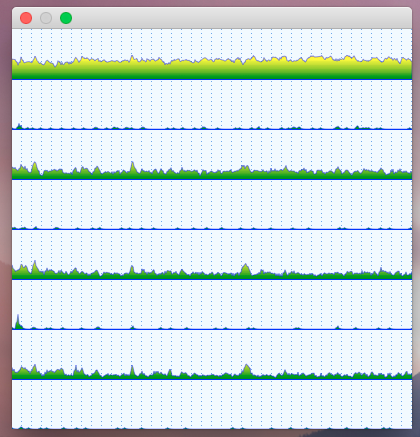
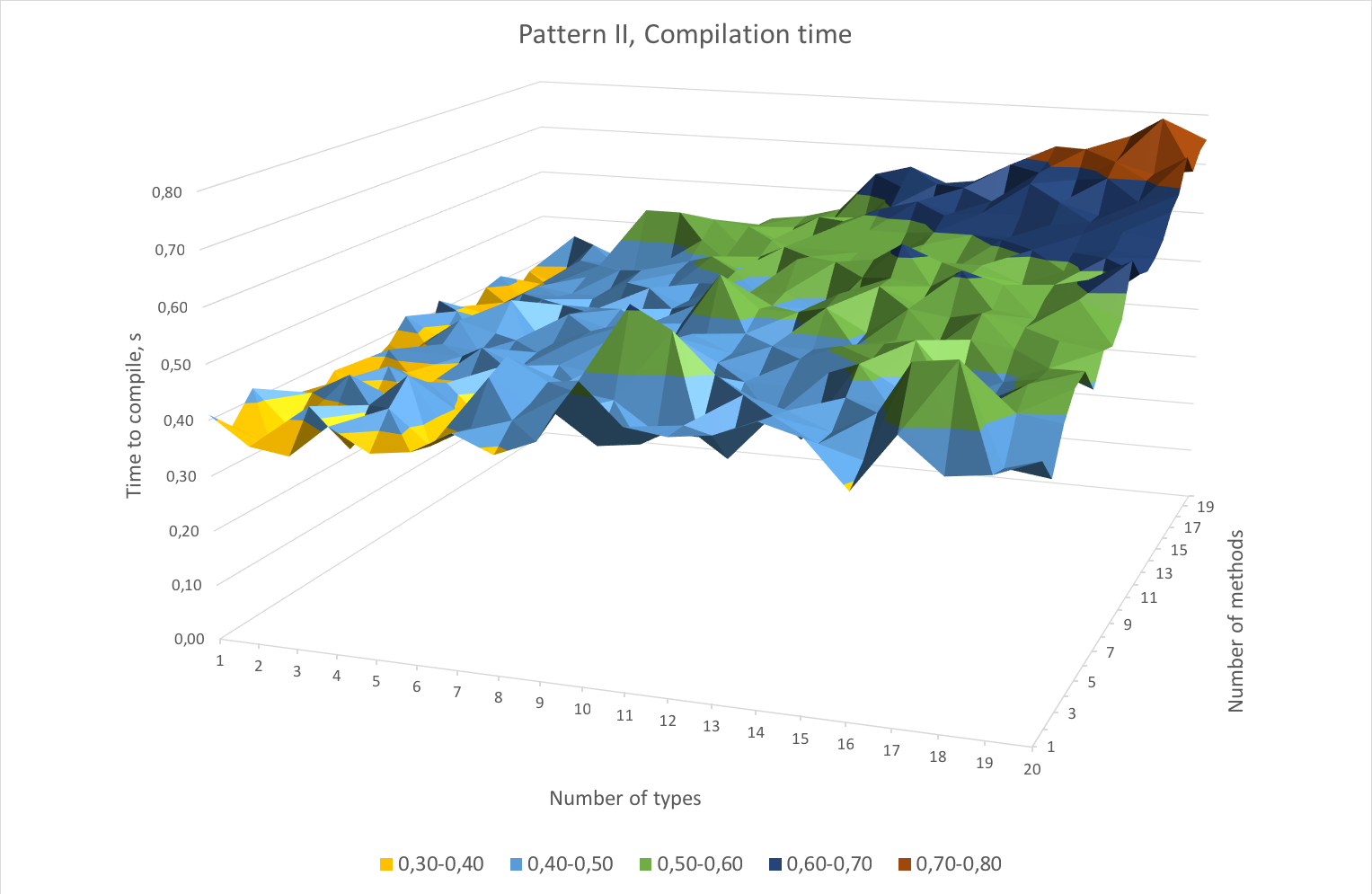
The graphs below show the scaling of the second pattern. The worst-case scenario takes 0.75s to compile instead of 2.73s with the first pattern. The object file is 4 times smaller in that case.
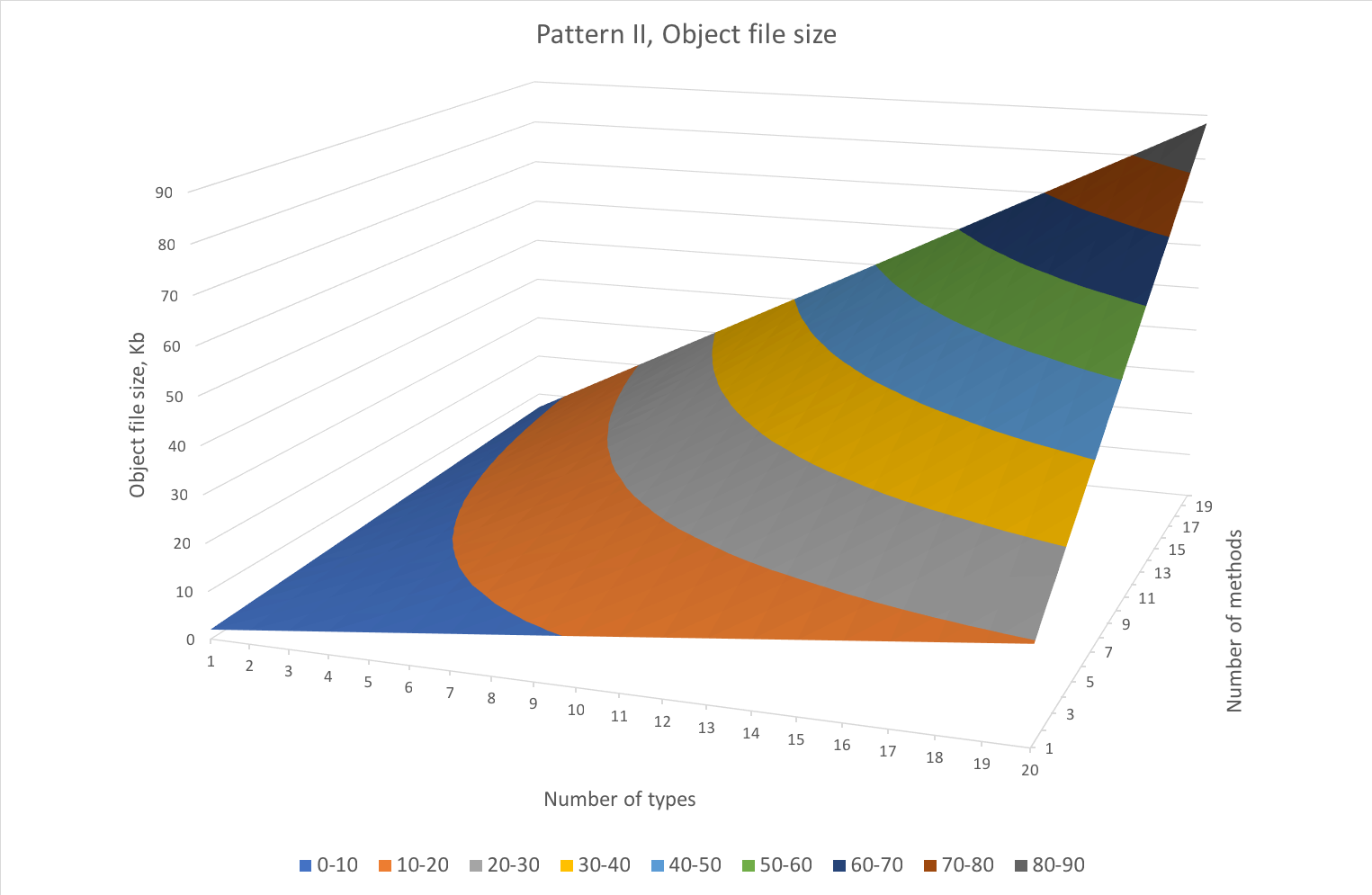
Of course, both patterns generated a completely synthetic code which is far too simple to look at concrete absolute numbers. Adding any reasonable logic into these methods would radically shift the results. But I guess it’s safe to assume that delta between these two patterns will not go anywhere – a compiler will still have to generate these instructions regardless of other complexity. So it should be fair to look at delta numbers:
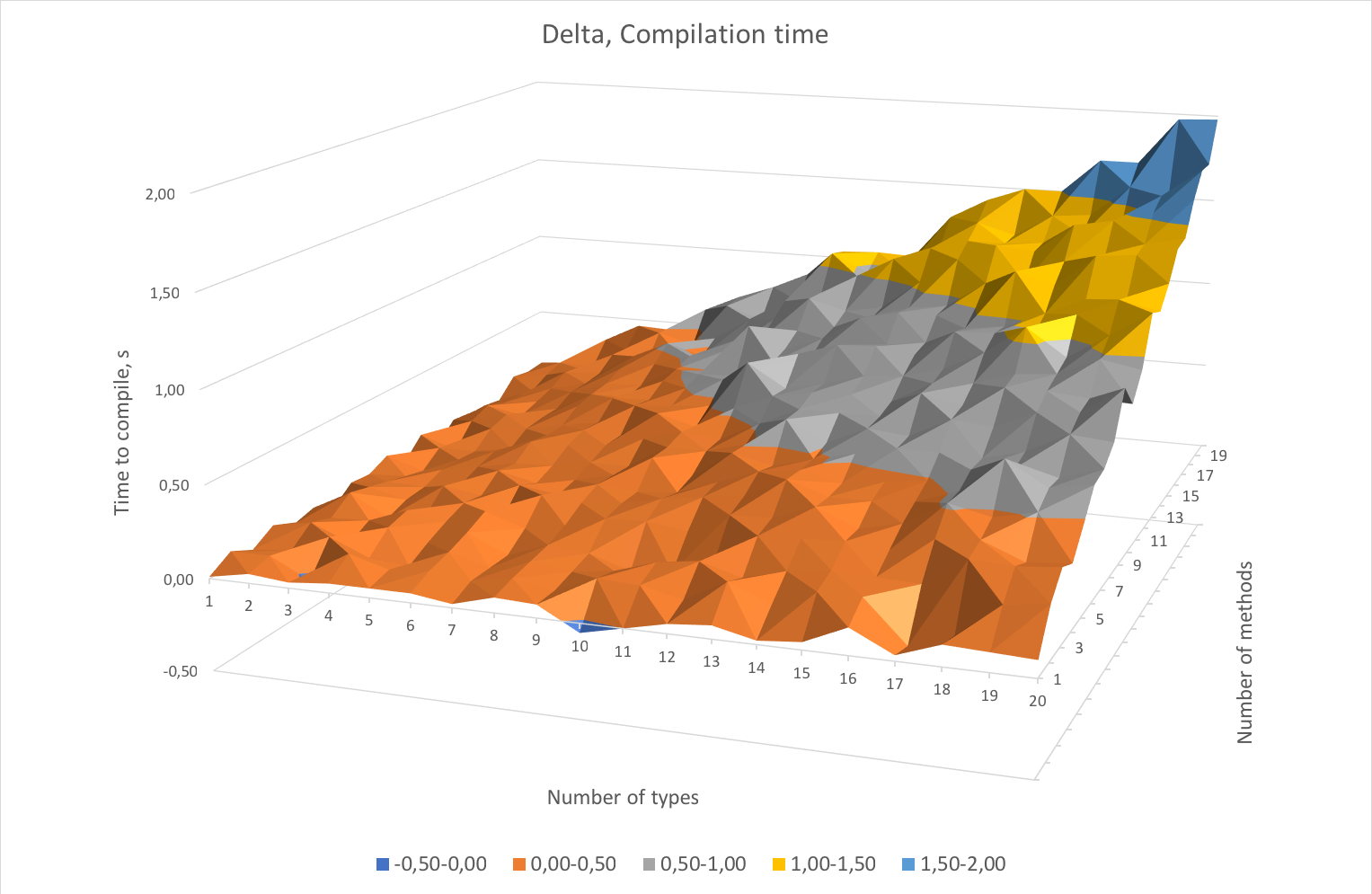
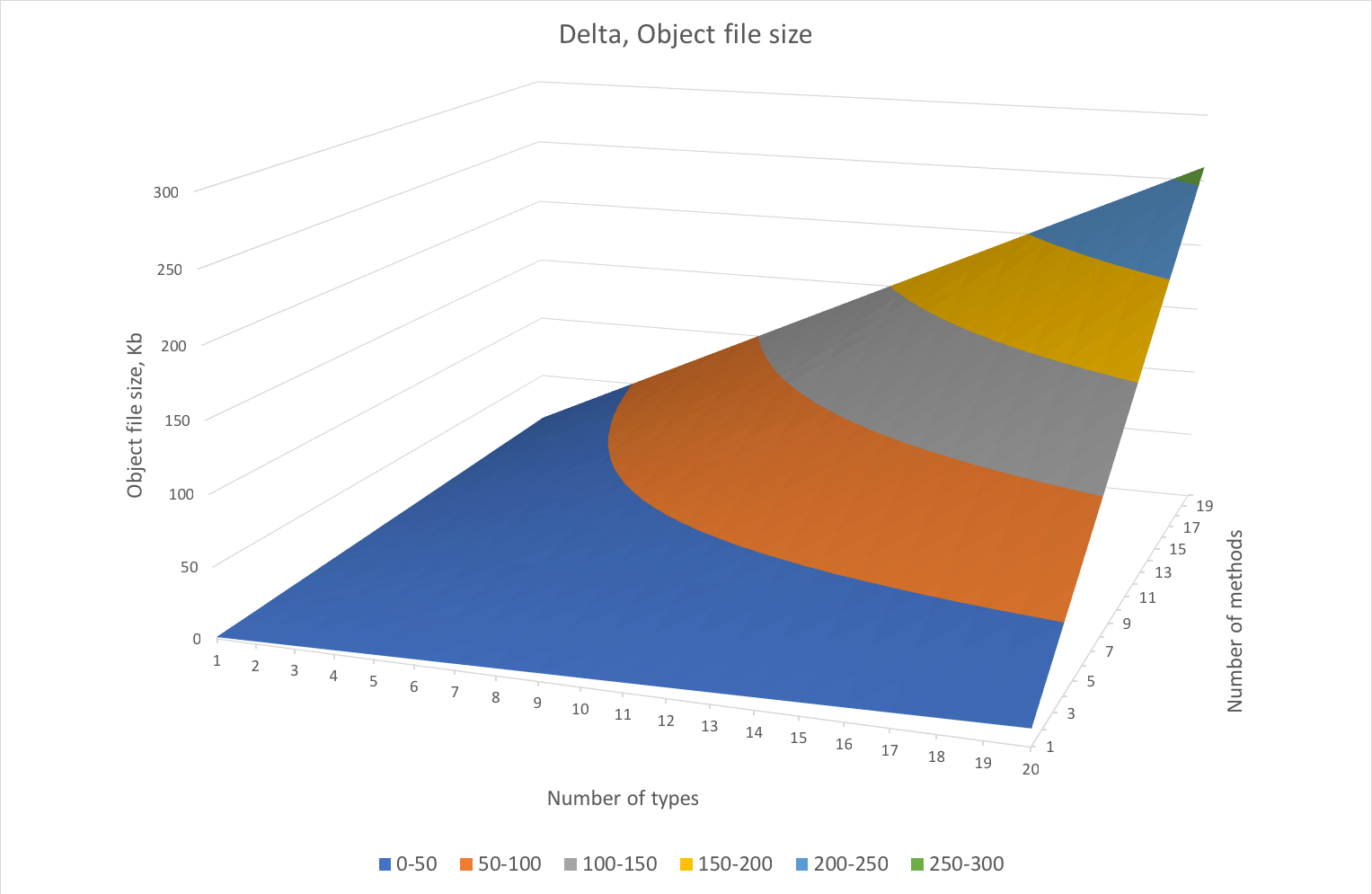
These delta numbers show something interesting. For instance, for the case of 10 methods and 10 instantiation types (which doesn’t seem too extreme), the difference is about half a second of compilation time per file. Or, to rephrase, there is a choice of two approaches:
a) Pattern I: clearer code – easier to maintain, but it costs 0.4 seconds of wait time per compilation per file;
b) Pattern II: a bit more obfuscated code – harder to maintain, but doesn’t introduce additional cost in terms of compilation time.
This choice, as usual in engineering, doesn’t provide a “right” option – it’s always a tradeoff. Often times, however, such choices are being done unconsciously just because something is considered to be a “default” way by the C++ community.
The “zero-cost abstractions” are sometimes being presented as the main C++ feature, but there are many hidden costs – graphs above show just one aspect of such penalties. The recent debate on Modern C++ vs. GameDev touched this problem and the ascetic approach of “C with classes” definitely has many valid points. At least such code compiles fast.