Any seasoned C++ programmer knows that object allocation does cost CPU cycles, and may cost lots of them. The language itself provides various object allocation types. Such mess might surprise folks who use other user-friendlier languages, especially languages with a garbage collection. But that’s only the beginning. Any C++ Jedi knows about custom allocation strategies, such as memory pools, buddy allocation, grow-only allocators, can write a generic-purpose memory allocator (probably quite a crappy one) and so forth.
Does it help? Sometimes usage of a custom allocator allows tuning up an application’s performance, by exploiting a specific knowledge about properties of the system.
Does it mean that it might be a good idea to write your own malloc() implementation? Absolutely not. It’s a good challenge for educational purposes, but almost never this will bring any performance benefits.
So what about Cocoa in this aspect?
On Foundation level, Objective-C once had some options to customize the allocation process via NSZone, but they were discarded upon a transition to the ARC. Swift, on the other hand, AFAIK doesn’t even pretend to provide any allocation options.
On CoreFoundation level, many APIs accept a pointer to a memory allocator (CFAllocatorRef) as the first parameter. kCFAllocatorDefault or NULL is passed to use the default allocator, i.e. CFAllocatorGetDefault(), i.e. kCFAllocatorSystemDefault in most cases. CoreFoundation also provides a set of APIs to manipulate the allocation process:
– CFAllocatorCreate
– CFAllocatorAllocate
– CFAllocatorReallocate
– CFAllocatorDeallocate
– CFAllocatorGetPreferredSizeForSize
– CFAllocatorGetContext
An overall mechanics around CFAllocatorRef is quite well documented and, even better, it’s always possible to take a look at the source code of CoreFoundation. So, it’s absolutely ok to use a custom memory allocator on the CoreFoundation level.
“What for?” might be a reasonable question here. Introducing any additional low-level components also implies some maintenance burden in the future, so there should be some heavy pros to bother with a custom memory allocation. Traditionally, the Achilles’ heel of generic-purpose memory allocators is a dealing with many allocations and consequent deallocations of small amounts of memory. There’re plenty of optimization techniques developed for such tasks, so why not check it on Cocoa?
Suppose we want to spend as less time on memory allocation as possible. Nothing is faster than allocating memory on the stack, obviously. But there are some issues with a stack-based allocation:
• The stack is not limitless. A typical program, which does nothing tricky, is very unlikely to hit the stack limit, but that’s not an advice to carelessly use alloca() everywhere – it will strike back eventually.
• Deallocating a stack-based memory in an arbitrary order is painful and requires some time to manage. In a perfect world, however, it would be great to have an O(1) time complexity for both allocation and deallocation.
• All allocated objects must be freed before an escaping out of allocator’s visibility scope, otherwise, an access to the “leaked” object will lead to an undefined behavior.
To mitigate these issues, a compromise strategy exists:
• Use a stack memory when possible, fall back to a generic-purpose memory allocator otherwise.
• Do increase a stack pointer on allocations, don’t decrease it upon deallocations.
In such case, allocations will be blazingly fast most of the time, while it’s still possible to process requests for big memory chunks. As for the third issue, it falls onto the developer, since the memory allocator can only help with some diagnostic. It’s incredibly easy to write such memory allocator, main steps are described below.
The stack-based allocator is conceptually a classic C++ RAII object. It’s assumed that the client source code will be compiled as C++ or as Objective-C++. The only public method, apart from the constructor and the destructor, provides a CFAllocatorRef pointer to pass into CoreFoundation APIs. The internal state of the allocator consists of the stack itself, a stack pointer, two allocations counters for diagnostic purposes and the CFAllocatorRef pointer.
struct CFStackAllocator
{
CFStackAllocator() noexcept;
~CFStackAllocator() noexcept;
inline CFAllocatorRef Alloc() const noexcept { return m_Alloc; }
private:
...
static const int m_Size = 4096 - 16;
char m_Buffer[m_Size];
int m_Left;
short m_StackObjects;
short m_HeapObjects;
const CFAllocatorRef m_Alloc;
};
To initialize the object, the constructor fills counters with defaults and creates a CFAllocatorRef frontend. Only two callbacks are required to build a working CFAllocatorRef: CFAllocatorAllocateCallBack and CFAllocatorDeallocateCallBack.
CFStackAllocator::CFStackAllocator() noexcept:
m_Left(m_Size),
m_StackObjects(0),
m_HeapObjects(0),
m_Alloc(Construct())
{}
CFAllocatorRef CFStackAllocator::Construct() noexcept
{
CFAllocatorContext context = {
0,
this,
nullptr,
nullptr,
nullptr,
DoAlloc,
nullptr,
DoDealloc,
nullptr
};
return CFAllocatorCreate(kCFAllocatorUseContext, &context);
}
To allocate a memory block, it’s only needed to check whether requested block could be placed in the stack buffer. In this case, the allocation process itself consists only of updating the free space counter. Otherwise, the allocation falls back to the generic malloc().
void *CFStackAllocator::DoAlloc
(CFIndex _alloc_size, CFOptionFlags _hint, void *_info)
{
auto me = (CFStackAllocator *)_info;
if( _alloc_size <= me->m_Left ) {
void *v = me->m_Buffer + m_Size - me->m_Left;
me->m_Left -= _alloc_size;
me->m_StackObjects++;
return v;
}
else {
me->m_HeapObjects++;
return malloc(_alloc_size);
}
}
To deallocate a previously allocated memory block, it’s only needed to check whether that allocation was dispatched to the malloc() and to call free() accordingly.
void CFStackAllocator::DoDealloc(void *_ptr, void *_info)
{
auto me = (CFStackAllocator *)_info;
if( _ptr < me->m_Buffer || _ptr >= me->m_Buffer + m_Size ) {
free(_ptr);
me->m_HeapObjects--;
}
else {
me->m_StackObjects--;
}
}
To measure the performance difference between a default Objective-C allocator, a default CoreFoundation allocator and the CFStackAllocator, the following task was executed:
Given N UTF-8 strings, calculate hash values of derived strings which are lowercase and normalized.
An Objective-C variant of the computation:
unsigned long Hash_NSString( const vector<string> &_data )
{
unsigned long hash = 0;
@autoreleasepool {
for( const auto &s: _data ) {
const auto nsstring = [[NSString alloc] initWithBytes:s.data()
length:s.length()
encoding:NSUTF8StringEncoding];
hash += nsstring.lowercaseString.decomposedStringWithCanonicalMapping.hash;
}
}
return hash;
}
A CoreFoundation counterpart of this task:
unsigned long Hash_CFString( const vector<string> &_data )
{
unsigned long hash = 0;
const auto locale = CFLocaleCopyCurrent();
for( const auto &s: _data ) {
const auto cfstring = CFStringCreateWithBytes(0,
(UInt8*)s.data(),
s.length(),
kCFStringEncodingUTF8,
false);
const auto cfmstring = CFStringCreateMutableCopy(0, 0, cfstring);
CFStringLowercase(cfmstring, locale);
CFStringNormalize(cfmstring, kCFStringNormalizationFormD);
hash += CFHash(cfmstring);
CFRelease(cfmstring);
CFRelease(cfstring);
}
CFRelease(locale);
return hash;
}
A CoreFoundation counterpart using a stack-based memory allocation:
unsigned long Hash_CFString_SA( const vector<string> &_data )
{
unsigned long hash = 0;
const auto locale = CFLocaleCopyCurrent();
for( const auto &s: _data ) {
CFStackAllocator alloc;
const auto cfstring = CFStringCreateWithBytes(alloc.Alloc(),
(UInt8*)s.data(),
s.length(),
kCFStringEncodingUTF8,
false);
const auto cfmstring = CFStringCreateMutableCopy(alloc.Alloc(), 0, cfstring);
CFStringLowercase(cfmstring, locale);
CFStringNormalize(cfmstring, kCFStringNormalizationFormD);
hash += CFHash(cfmstring);
CFRelease(cfmstring);
CFRelease(cfstring);
}
CFRelease(locale);
return hash;
}
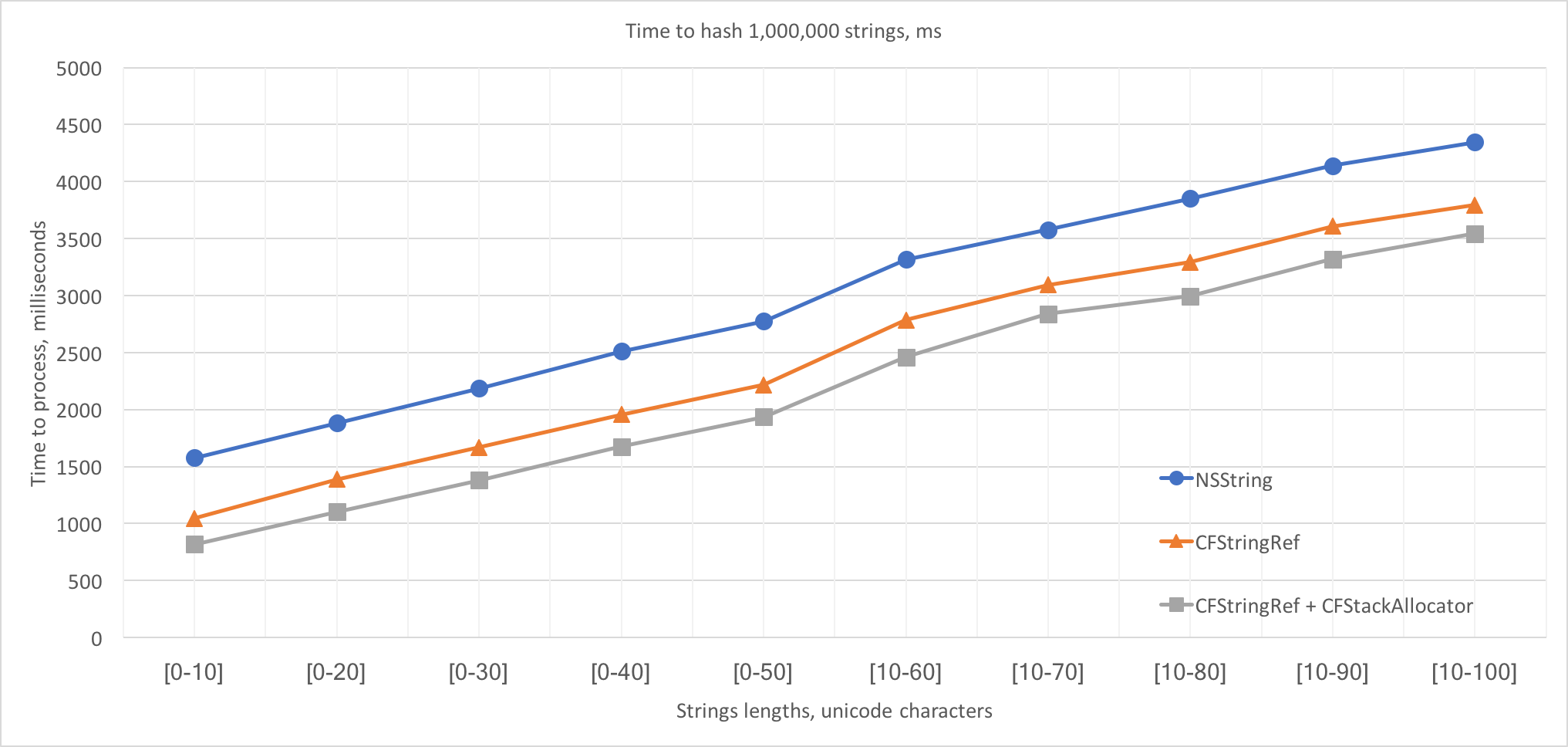
And here are the results. These functions were called with the same data set consisting of 1,000,000 randomly generated strings with varying lengths.

On the provided data sets range, the CoreFoundation+CFStackAllocator implementation variant is 20%-50% faster than the pure Objective-C implementation and is 7%-20% faster than the pure CoreFoundation implementation. It’s easy to observe that Δ between timings is almost constant and represents the difference between times spent in the management tasks. To be precise, the time spent in management tasks in the CoreFoundation+CFStackAllocator variant is ~800ms less than in the Objective-C variant and is ~270ms less than in the pure CoreFoundation variant. Divided by the strings amount, this Δ is ~800ns and ~270ns per string accordingly.
The stack-based memory allocation is a micro-optimization, of course, but it might be very useful in a time-critical execution path. The complete source code of the CFStackAllocator and of the benchmarking is available in this repository: https://github.com/mikekazakov/CFStackAllocator.