Introduction
This blog post describes another IO2D demo I wrote as a showcase of the library’s capabilities. The demo is a simple yet working GIS renderer. The OpenStreetMap service is used as a raw data provider, allowing for the visualization of any reasonably sized rectangular region. The demo supports querying OSM servers directly or loading existing data files. The entire source code of the sample is less than 800 lines of code, of which 250 lines deal with the rendering itself and another 360 lines handle the data model.
OpenStreetMap API
OpenStreetMap has an API which lets you download map data specified by an arbitrary coordinate bounding box. This interface has a number of limitations related to data transfer. For instance, the API might not fetch more than 50K nodes in some cases. Also, the interface may provide an incomplete geometry, which happens when a complex region is only partially covered by the bounding box. The latter is especially apparent with water regions like rivers, lakes and coasts. These limitations are however quite tolerable for sample code.
The API is accessible via the following HTTP GET request: /api/0.6/map?bbox=MinLong,MinLatt,MaxLong,MaxLatt. For example, these are coordinates for Rapperswil:
wget https://api.openstreetmap.org/api/0.6/map?bbox=8.81598,47.22277,8.83,47.23
The returned data will contain a raw OpenStreetMap XML file with nodes, ways and relations between them.
External libraries
Obviously (no sarcasm implied), C++ has no standard networking capabilities, so some external facility is required to download map data. Boost.Beast was chosen to talk with OSM servers in the sample code. Once a file is received, that XML has to be parsed. PugiXML was employed to deal with it.
Data representation
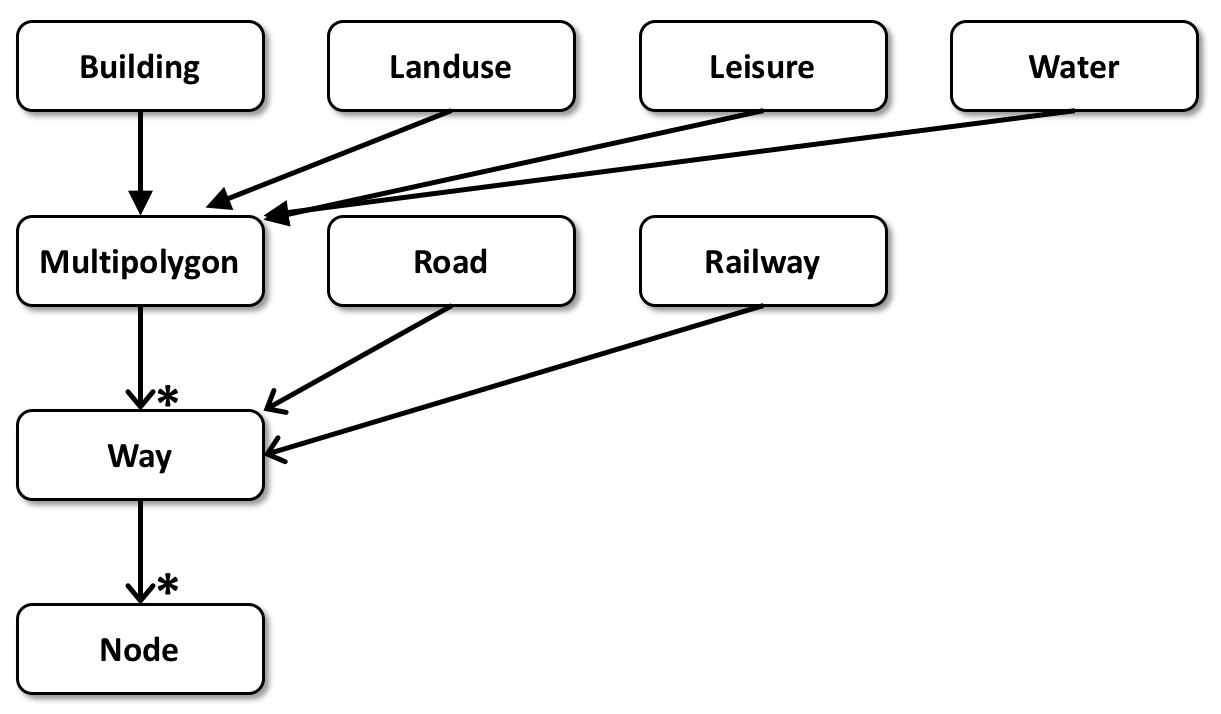
This demo uses a very simple interpretation of OpenStreetMap data. Instead of trying to handle myriads of different tags, it grabs objects of several types and ignores everything else. The Model class transforms the input XML file into a set of linear containers which hold all information required to render the map. The OSM format uses 64-bit integers to uniquely identify entities and to maintain connections, which assumes storing objects in some kind of a hash map. The Model class transforms these unordered identifiers into raw array indices to reduce the impact on the memory subsystem and to enforce consistency.
The transformed map data is accessible via several POD types. A Node object represents some point of interest and carries just a pair of coordinates. A Way object represents a collection of Nodes. A Road and a Railway point at some Way to describe an underlying geometry. A Road also has its enumeration type, like Motorway or Footway, to visually distinguish between different types of roads. A Multipolygon represents a set of outer and inner polygons, which basically means two sets of Way objects. Building, Leisure, Landuse and Water are different types of Multipolygon objects. Landuse also has type information, like Commercial, Construction, Industrial etc. The overall logic model looks like this:
Coordinates transformations
OpenStreetMap works with latitudes and longitudes, so these coordinates must be projected into the convenient Cartesian coordinate system. A simple Pseudo-Mercator metric projection is used to transform input coordinates:
auto pi = 3.14159265358979323846264338327950288; auto deg_to_rad = 2. * pi / 360.; auto earth_radius = 6378137.; auto lat2ym = [&](double lat) { return log(tan(lat * deg_to_rad / 2 + pi/4)) / 2 * earth_radius; }; auto lon2xm = [&](double lon) { return lon * deg_to_rad / 2 * earth_radius; };
It is also worth noting that a precision of 32-bit float values is not enough, so 64-bit double values are used for initial storage and projection. Once Cartesian coordinates are calculated, they are translated and scaled into the range of [0..1].
Polygons composition
OSM lets polygons to be defined as a composition of multiple non-closed Ways. The idea behind this is a sharing of Ways data between several adjacent areas to remove the necessity to declare the same border twice. Such an approach leads to an intermediate step of composing polygons out of pieces. To complicate matters, OSM does not mandate a strict order of Ways declaration and only requires that a closed polygon should be composable out of a given set. This even includes a possible interpretation of Way’s nodes in the reversed order: ABC + EDC + AFE = ABCDEF. The goal of this step is to get a set of closed Ways, so this data can be fed to a graphics API later. The sample code implements the polygons composition in a pretty blunt brute-force manner. This implementation works well enough on real data, but in theory, its performance may significantly degrade due to the high algorithmic complexity.
Rendering
Once the data is parsed and transformed, the Render class can start drawing the map. The drawing process is sequential and follows this order: landuse regions, leisure regions, water regions, railways, highways and buildings.
Each object has to be represented as a path before it can be drawn. Two methods do that: PathFromWay and PathFromMP. The difference between them is that PathFromWay deals with non-closed ways while PathFromMP composes a path from a collection of closed Ways. Straight lines are used to connect nodes along a Way:
io2d::interpreted_path Render::PathFromWay(const Model::Way &way) const { if( way.nodes.empty() ) return {}; const auto nodes = m_Model.Nodes().data(); auto pb = io2d::path_builder{}; pb.matrix(m_Matrix); pb.new_figure( ToPoint2D(nodes[way.nodes.front()]) ); for( auto it = ++way.nodes.begin(); it != std::end(way.nodes); ++it ) pb.line( ToPoint2D(nodes[*it]) ); return io2d::interpreted_path{pb}; }
Each region type has its visual properties like fill color, outline color, stroke width and dashes pattern. These properties are defined once during construction of a Render object and most of the times are used as-is. The exception is road/railroad width, which is defined in meters and has to be scaled into pixel width according to a map scale and a window size.
This render code utilizes only solid color brushes, however nothing stops us from using image brushes instead. The main issue with them is that such images need to be drawn by someone and IMHO the programmer art should be avoided like the plague.
Some regions might have holes inside, which is specified via separation of outer and inner polygons. The demo combines such polygons into a single path which is drawn under io2d::fill_rule::winding rule.
The drawing itself is pretty straightforward, for example, these 7 lines of code display the buildings on the map:
void Render::DrawBuildings(io2d::output_surface &surface) const { for( auto &building: m_Model.Buildings() ) { auto path = PathFromMP(building); surface.fill(m_BuildingFillBrush, path); surface.stroke(m_BuildingOutlineBrush, path, std::nullopt, m_BuildingOutlineStrokeProps); } }
Examples
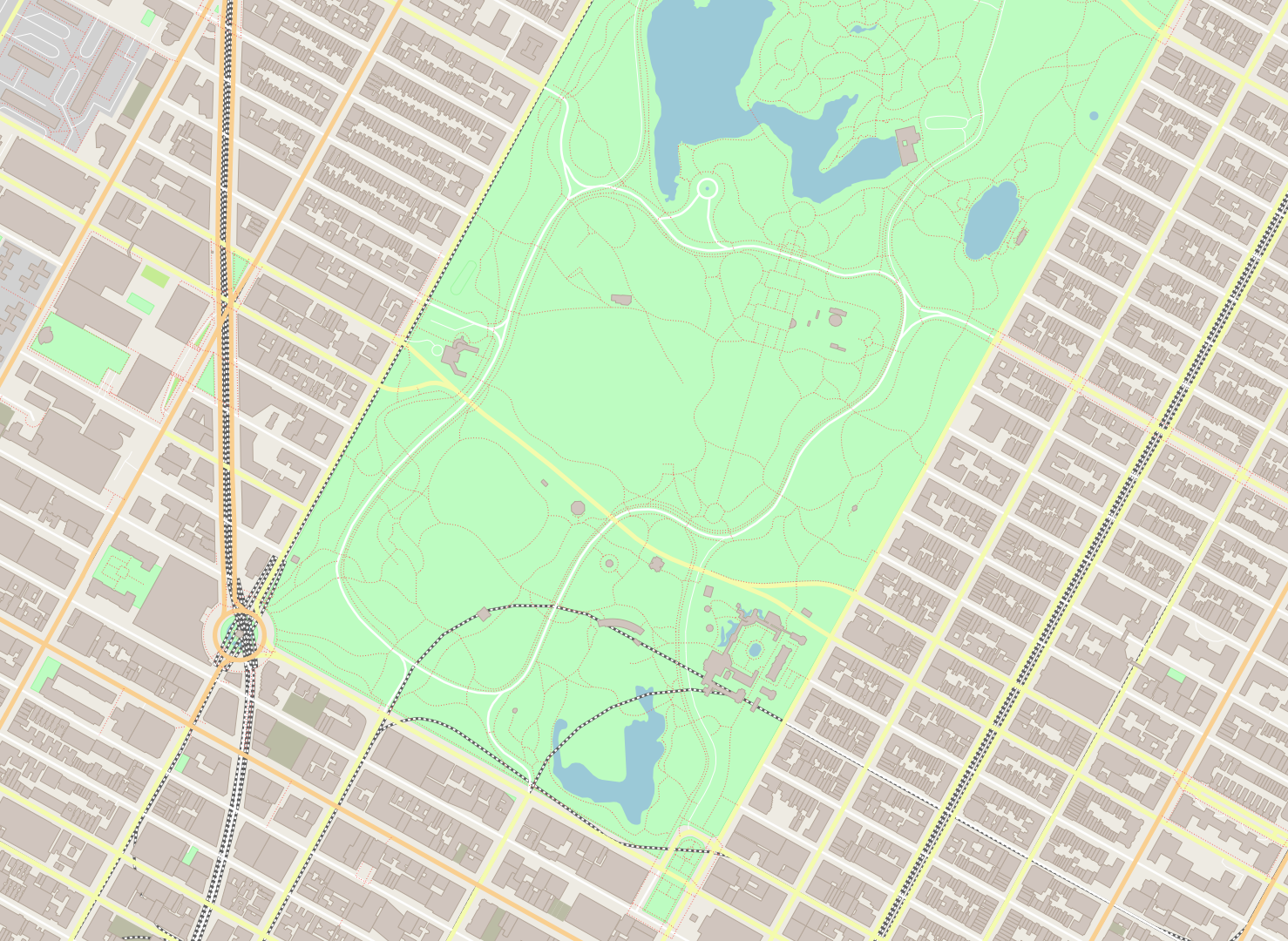
Central Park:
./maps -b -73.9866,40.7635,-73.9613,40.7775
Acropolis of Athens:
./maps -b 23.7125,37.9647,23.7332,37.9765
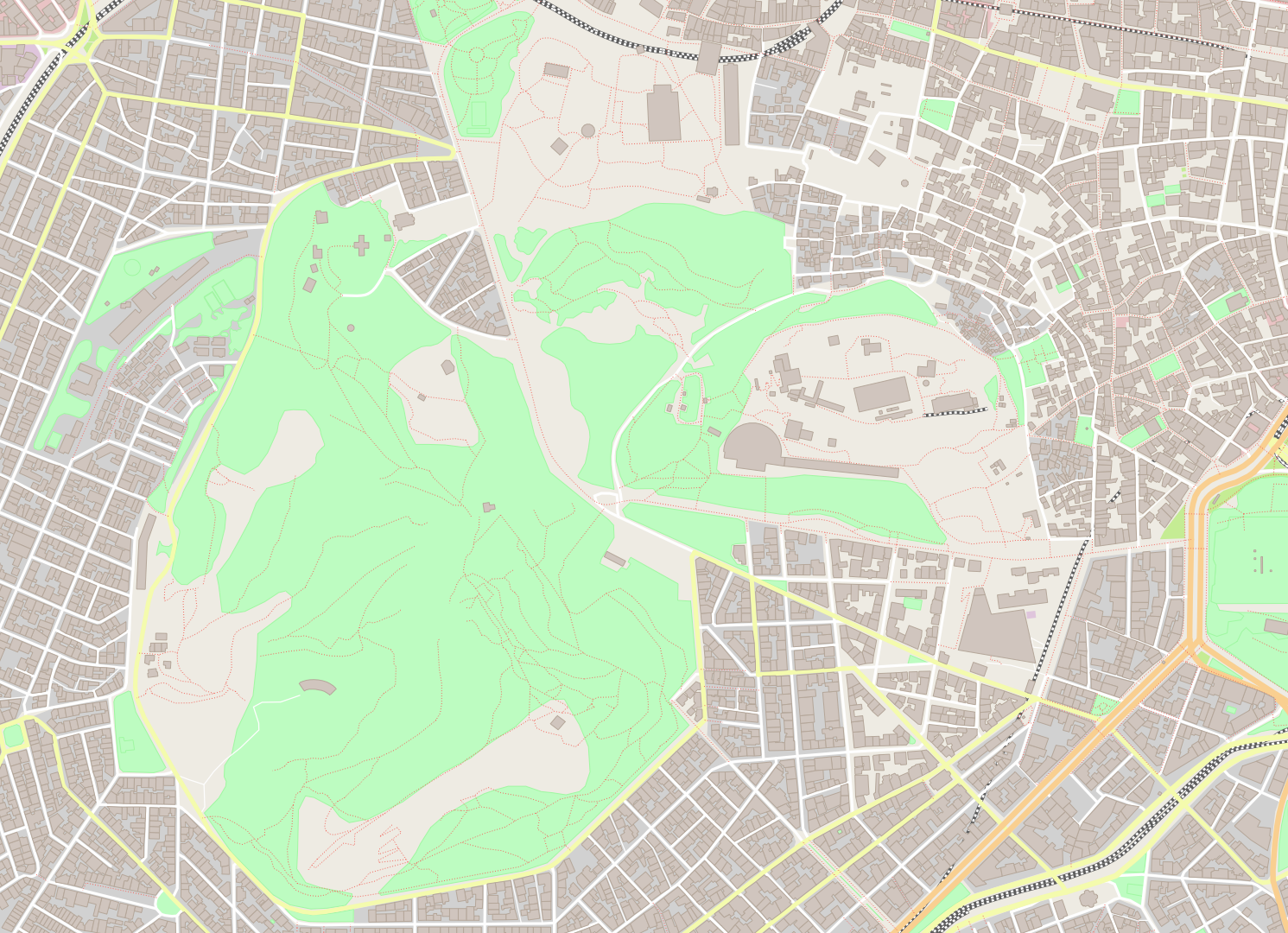
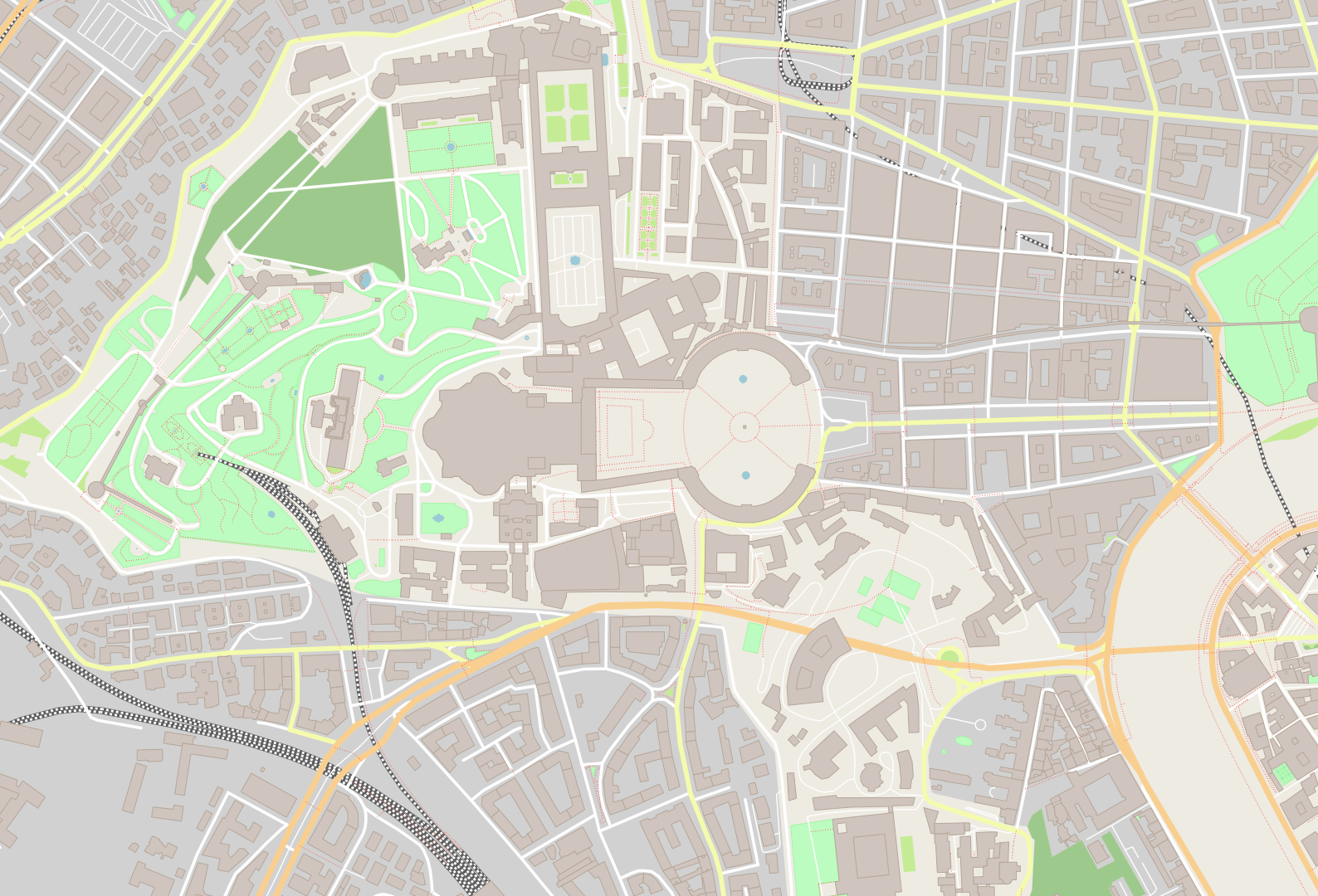
Vatican:
./maps -b 12.44609,41.897,12.46575,41.907
Performance statistics
This demo renders the entire graphics set from scratch every frame. This, of course, is not how such software usually behaves, but for the sake of simplicity, the choice was not to introduce any caching. So how does the Reference Implementation cope with this task? For testing purposes, I used the Core Graphics backend running on macOS 10.13. The source code was compiled in Xcode9.3 in Release configuration. The hardware underneath is an old 2012 MacMini with a 2,3GHz Core i7 processor. The maps were rendered at the resolution of 1920 x 1080.
| Dataset | Central Park | Acropolis of Athens | Vatican |
| Nodes | 36,909 | 51,126 | 27,614 |
| Ways | 4,636 | 6,105 | 3,410 |
| Roads | 1,082 | 989 | 1,060 |
| Railroads | 41 | 42 | 44 |
| Buildings | 2,329 | 4,336 | 889 |
| Leisures | 44 | 77 | 101 |
| Waters | 13 | 0 | 31 |
| Landuses | 23 | 66 | 66 |
| FPS | 11 | 9 | 14 |
Conclusion
So, it takes 90ms to display the Central Park dataset, which consists of ~37K points in ~3,5K paths. Not a terrible result for a software rendering engine, which shows that the library is clearly capable of handling a casual graphics output. Of course, a hardware-accelerated backend like Direct2D would perform much faster, but it’s not here yet.
The sample’s source code is available here: https://github.com/mikebmcl/P0267_RefImpl/tree/master/P0267_RefImpl/Samples/Maps.